
Tệp robots.txt là một tệp văn bản được đặt tại thư mục gốc của website nhằm hướng dẫn các công cụ tìm kiếm như Googlebot cách thu thập thông tin (crawl) trên trang web. Đây là công cụ cơ bản giúp quản lý quyền truy cập của trình thu thập dữ liệu đến các phần khác nhau trên trang, từ đó ảnh hưởng đến cách trang được lập chỉ mục (indexing) trên Google.
NỘI DUNG CHÍNH
Vai trò của robots.txt trong SEO
Việc thiết lập robots.txt đúng cách có thể hỗ trợ chiến lược SEO bằng cách kiểm soát tài nguyên mà bot truy cập. Bạn có thể chặn bot truy cập vào các phần không quan trọng hoặc lặp lại như trang tìm kiếm nội bộ, tài nguyên động, hoặc các tập tin lớn không cần thiết. Điều này giúp tập trung khả năng thu thập dữ liệu của bot vào những nội dung chính có giá trị SEO cao hơn, từ đó cải thiện hiệu suất lập chỉ mục và xếp hạng trên công cụ tìm kiếm.
Tuy nhiên, điều quan trọng cần nhớ là robots.txt không phải công cụ bảo mật. Các trang bị chặn bởi robots.txt vẫn có thể được truy cập nếu người khác biết URL, và chúng cũng có thể xuất hiện trong kết quả tìm kiếm nếu được liên kết từ nơi khác, trừ khi có thêm các thẻ meta noindex hoặc x-robots-tag.
Nguyên tắc tạo tệp robots.txt
Để tạo một tệp robots.txt hiệu quả, bạn cần tuân theo một số quy tắc chính. Trước hết, tệp này luôn phải được đặt tại thư mục gốc của website (ví dụ: https://example.com/robots.txt). Mỗi dòng trong tệp xác định lệnh cụ thể cho một nhóm user-agent (tức là bot tìm kiếm), trong đó phổ biến nhất là User-agent: * để áp dụng cho tất cả các bot.
Các lệnh phổ biến bao gồm Disallow để ngăn bot truy cập vào một thư mục hoặc trang cụ thể, và Allow để cho phép truy cập đến một phần cụ thể dù đã chặn thư mục cha. Nếu bạn không muốn hạn chế bất kỳ nội dung nào, tệp robots.txt có thể để trống hoặc không tồn tại. Ngoài ra, bạn có thể khai báo đường dẫn đến sitemap XML trong tệp này để giúp bot hiểu cấu trúc trang web tốt hơn.
Cấu trúc cơ bản của tệp
User-agent: [tên trình thu thập dữ liệu]
Disallow: [đường dẫn không cho phép thu thập]
Allow: [đường dẫn cho phép thu thập]
Sitemap: [URL của sơ đồ trang web]
Ví dụ tệp chuẩn sẽ có nội dung như sau:
User-agent: Googlebot
Disallow: /private/
User-agent: *
Allow: /
Sitemap:
Chú thích:
- Dòng User-agent chỉ định trình thu thập dữ liệu mà quy tắc áp dụng.
- Disallow ngăn trình thu thập truy cập vào đường dẫn cụ thể.
- Allow cho phép truy cập vào đường dẫn cụ thể, ngay cả khi thư mục cha bị chặn.
- Sitemap cung cấp đường dẫn đến sơ đồ trang web để hỗ trợ trình thu thập dữ liệu.
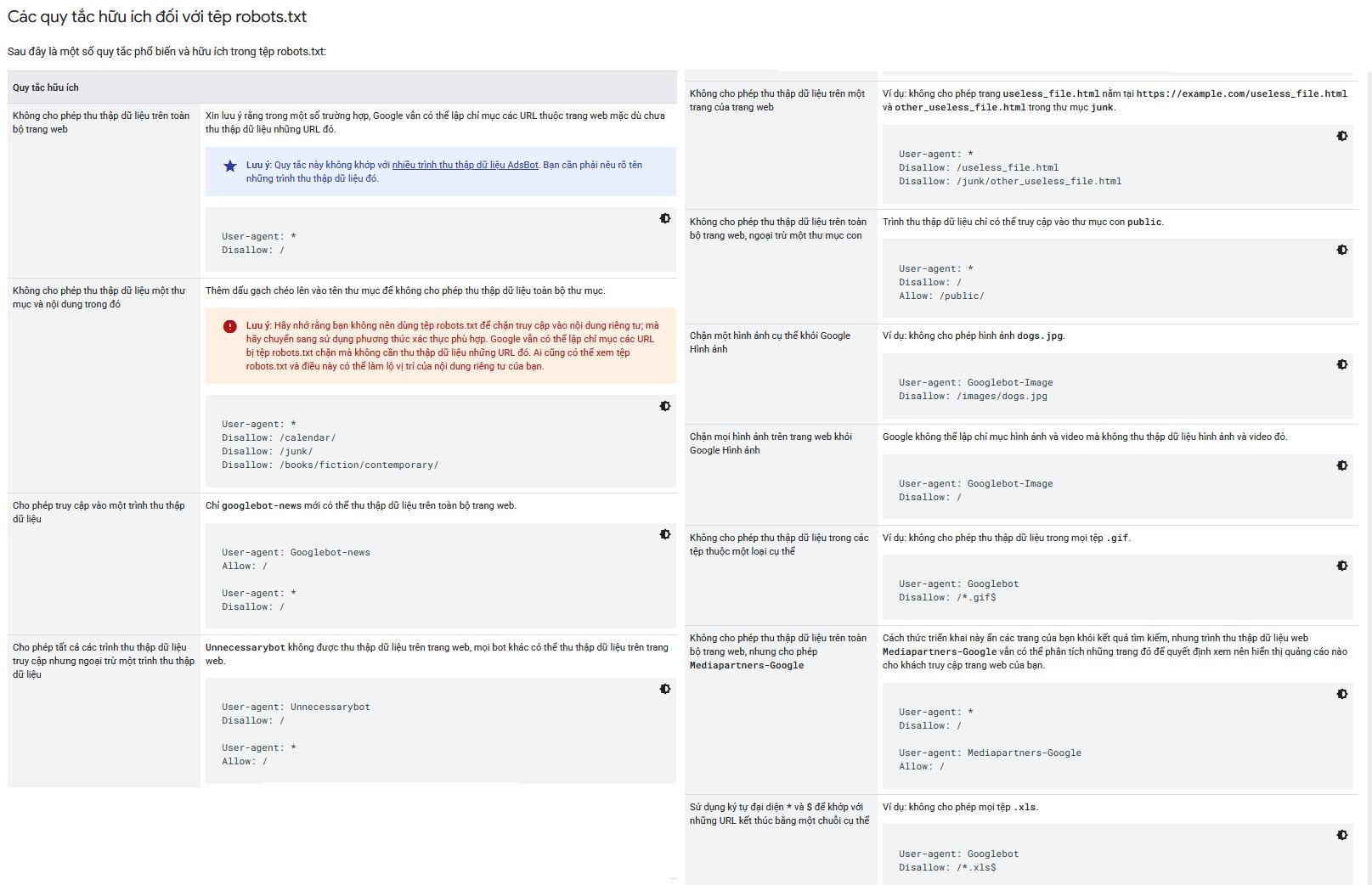

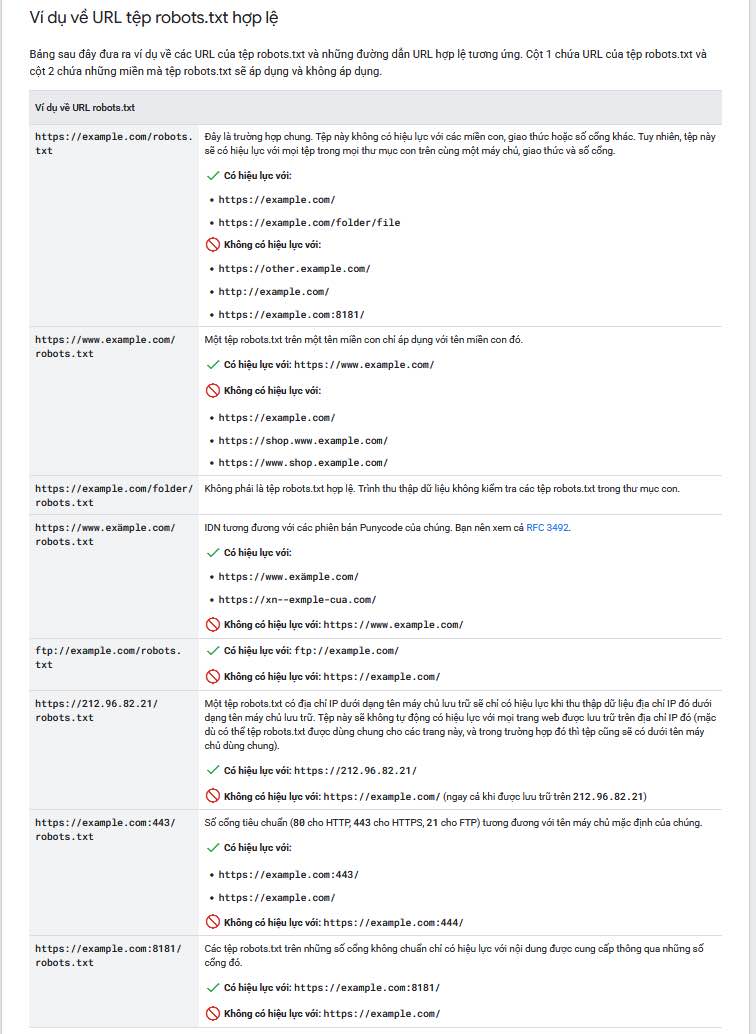

Những lưu ý khi sử dụng robots.txt
Google khuyến nghị bạn nên kiểm tra và cập nhật tệp robots.txt định kỳ để đảm bảo các chỉ dẫn vẫn còn phù hợp với cấu trúc và chiến lược SEO hiện tại của trang web. Bạn có thể dùng công cụ kiểm tra robots.txt trong Google Search Console để kiểm tra xem tệp hiện tại có chặn nhầm những nội dung quan trọng hay không.
Trong một số trường hợp, thay vì sử dụng robots.txt, bạn nên dùng các phương pháp khác như thẻ noindex trong HTML hoặc tiêu đề HTTP để kiểm soát việc lập chỉ mục. robots.txt phù hợp nhất cho việc kiểm soát thu thập dữ liệu, không phải để ngăn xuất hiện trên Google.
Ghi chú:
+ Bạn phải đặt đúng tên robots.txt, có chữ (s) nhé. Nhiều người viết robot.txt là sai.
+ Nếu bạn thiết lập tệp robots.txt ảo thông qua plugin Yoast seo hay Rankmath, thì không cần phải thiết lập tệp này trong thư mục gốc nữa.
———————————–
Nguồn tham khảo
https://developers.google.com/search/docs/crawling-indexing/robots/create-robots-txt?hl=vi
https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt?hl=vi